We’ve spent two years throwing LLMs at production problems and watching them fail in slow motion. The model isn’t the bottleneck anymore. The context is.
Every agent I’ve seen collapse in production didn’t fail because the model was too dumb. It failed because the context window turned into a landfill. The agent couldn’t find the relevant signal, the system prompt got buried under five hundred lines of chat history, and the entire loop started hallucinating its own state. That’s not a model problem. That’s a context engineering problem.
I’m Uddit, and I build agentic systems for a living. After shipping a few of these into real user hands, I’ve come to one conclusion: context engineering is the missing infrastructure layer. You can have the best model, the slickest orchestration framework, the fastest vector store. If you don’t manage context with the same rigor you manage memory or compute, your agent will hit a wall at week two of production.
Let me show you what that wall looks like, and how to engineer your way past it.
Why Context Engineering Is the New Infrastructure Battleground
The old stack was simple: prompt in, answer out. You could get away with a static system prompt and a few examples. But agents changed the game. An agent doesn’t produce one answer. It produces a loop of observations, actions, and reflections. Each step adds tokens to the context. Each turn creates history that the next turn must understand.
Basis Set recently published a piece arguing that agents broke the old infrastructure, and I think they’re right. The core insight is that agents are stateful, stateful systems require memory, and memory is fundamentally a context management problem. You can’t just shove everything into a single window and hope the model figures it out. The model doesn’t have infinite attention. And even if it did, the cost would kill you.
I’ve seen teams burn through $10,000 in a week because their agent’s context grew linearly with each loop. Every iteration appended the full conversation history. By day three, each call cost more than a cup of coffee. By day seven, the agent was repeating itself. That’s not a scaling problem. That’s a design failure.
The battleground is shifting from “which model is best” to “how do we feed the model the right information at the right time.” That’s context engineering. It’s the discipline of sizing, scoping, sequencing, and pruning the context window so the model sees exactly what it needs, nothing more.
What is context engineering, exactly? It’s the systematic design and management of the information that goes into an LLM’s context window. It includes deciding how much history to retain, how to prioritize recent vs. important information, how to summarize past turns, and how to structure the input so the model can navigate it efficiently. It’s not a one-time prompt design. It’s a continuous, runtime process.
The Hidden Failure Mode: Context Overload and Drift
Let me tell you about the first time I watched an agent drift off a cliff. We had a customer support agent that handled refund requests. It worked beautifully for the first ten interactions. Then, on the eleventh, it started asking the user for their grandmother’s maiden name. Not because it was malicious. Because the context window had accumulated so much irrelevant chit-chat that the model lost sight of the current task.
This is context drift. It happens when the model’s attention is diluted by stale or irrelevant information. The symptoms are subtle at first: the agent takes longer to respond, its answers become generic, and then it starts hallucinating facts from earlier turns. You debug it, you see the system prompt is still there, the instructions are correct, but the model is reading a twenty-page conversation history and trying to find the needle.
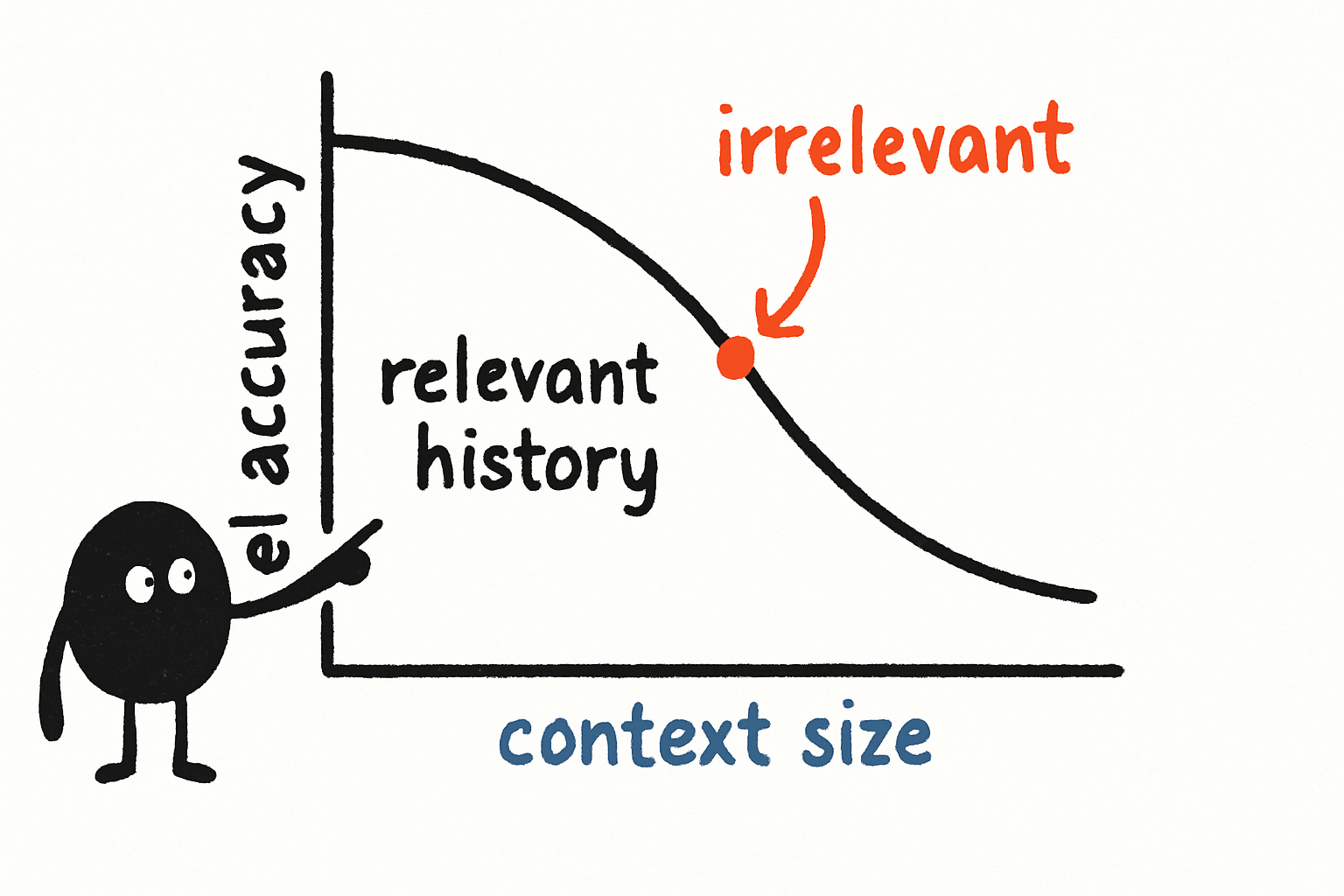
The research backs this up. LiveBench and the major LLM evaluation benchmarks consistently show that models degrade as context length increases, especially when the relevant information is buried in the middle. The “lost in the middle” problem is real. Models are good at recalling the first and last parts of a context window. The middle? Forget it.
Context overload is the other side of the coin. It’s not just about drift. It’s about cost and latency. Every token in the context window costs compute. If you’re running a loop that appends a 4,000-token history every turn, you’re paying for a 4,000-token inference each time, even if the model only needs the last 500 tokens. That’s wasteful. More importantly, it’s slow. Your agent’s latency goes from 200 milliseconds to 2 seconds, and your users feel it.
How do you diagnose context drift in a running agent? Look for three signs. One: the agent starts repeating itself or asking the same question twice. Two: it references information from earlier turns that is no longer relevant. Three: its responses become longer and more generic, as if it’s hedging. If you see any of those, your context is drifting.
A Framework for Context Engineering: Sizing, Scoping, and Sequencing
I’ve settled on a three-axis framework that I use for every agent I build. It’s not academic. It’s what works in production.
Sizing is about deciding how much context to give the model. The naive approach is “as much as possible.” The engineering approach is “as little as necessary.” I start by defining a token budget for each turn. For a simple classification task, that might be 500 tokens. For a complex reasoning loop, maybe 4,000. The key is to enforce the budget at the application layer, not rely on the model to ignore irrelevant tokens.
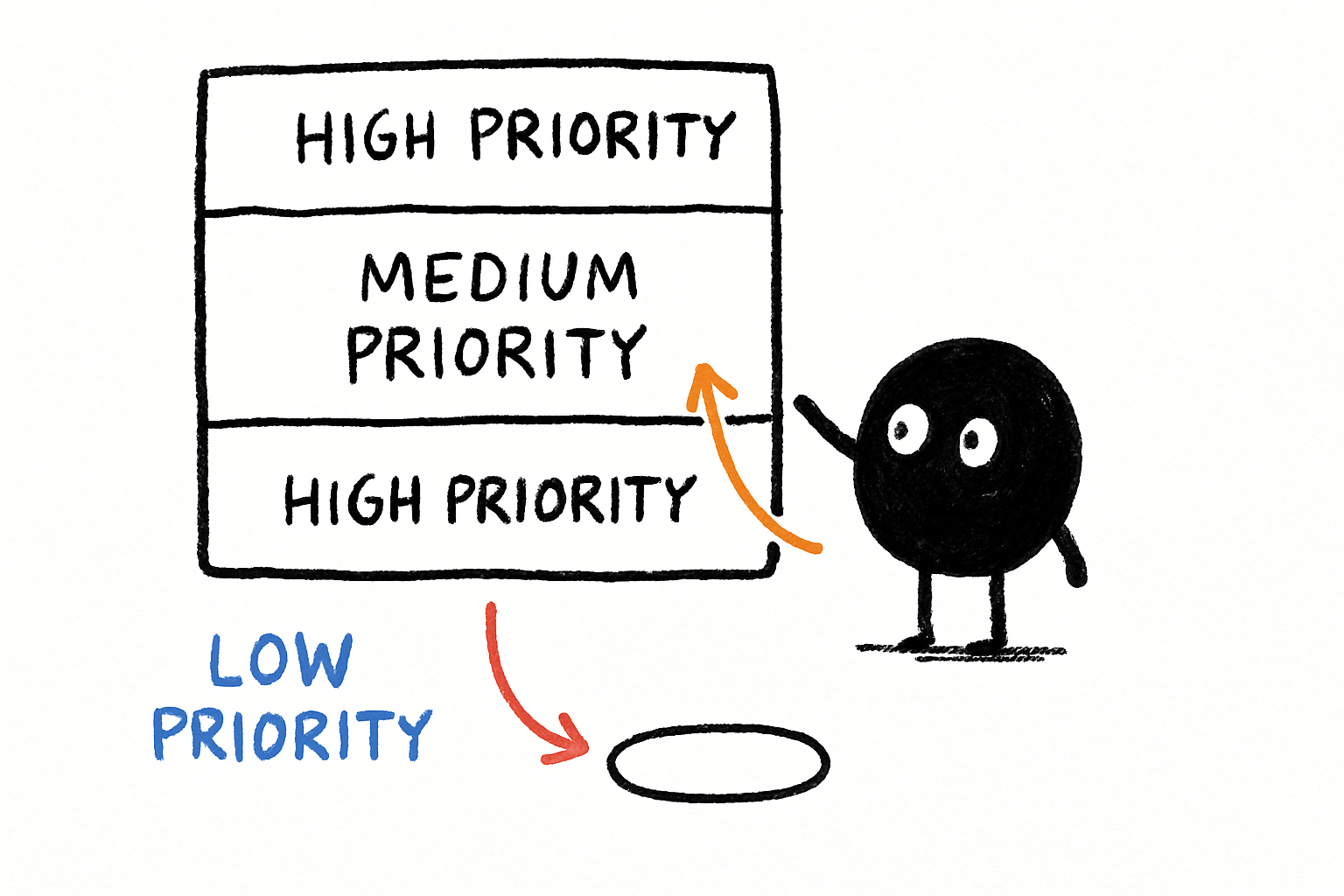
Scoping is about deciding what goes into the context. I use a priority system. The system prompt is always first. Then the most recent user input. Then a compressed summary of the conversation history. Then, if there’s room, relevant retrieved documents. Everything else gets dropped. I’ve seen teams try to include the full chat history, the full knowledge base, and the full tool output in one window. That’s not context engineering. That’s context dumping.
Sequencing is about ordering the information within the window. This is where the “lost in the middle” problem bites you. I put the most critical information at the beginning and the end. The system prompt goes first. The current user query goes last. Summaries and history go in the middle. If I need to include a long document, I break it into chunks and only include the most relevant chunk, placed near the end.
Here’s a concrete example. I built a code review agent that processes pull requests. The naive version included the entire diff, the entire conversation history, and the entire repo context in one call. It was slow, expensive, and often missed the key change. The engineered version does this:
- Sizes the context to 2,000 tokens.
- Scopes it to the diff summary, the most recent comment, and a one-sentence summary of the conversation history.
- Sequences it with the system prompt first, the diff summary second, the recent comment last.
The result? Same accuracy, 80% lower cost, 3x faster.
Practical Patterns: Dynamic Context Windows, Priority Queues, and Summarization Pipelines
Theory is nice. Let me give you patterns you can implement tomorrow.
Dynamic context windows. Don’t use a fixed token limit. Use a sliding window that adapts to the task. For a simple Q&A agent, I use a window of 1,000 tokens. For a multi-step reasoning agent, I dynamically expand the window to 4,000 tokens only when the model requests it. The trick is to let the agent signal when it needs more context, rather than assuming it always does. This reduces average cost by 40-60%.
Priority queues for context. I treat the context window like a cache. Every piece of information has a priority score. System prompts get priority 1. User inputs get priority 2. Tool outputs get priority 3. Conversation history gets priority 4. When the window is full, I evict the lowest-priority items first. This ensures that the model always sees the most critical information, even under memory pressure.
Summarization pipelines. This is the most impactful pattern. Instead of appending raw history, I run a separate summarization step that compresses the last N turns into a 200-token summary. That summary goes into the context. The raw history goes into a database. If the model needs to recall a specific detail, it can query the database. But most of the time, the summary is enough. This cuts context size by 70% without losing signal.
I learned this pattern from watching how Anthropic’s Claude handles long documents. Their approach is to chunk, summarize, and then only include the relevant chunks in the context. It’s not magic. It’s engineering.
What’s the simplest context engineering pattern you can start with today? Implement a summarization step. After every three turns, compress the conversation into a one-paragraph summary. Replace the raw history with that summary in the next call. You’ll see an immediate improvement in both cost and accuracy.
How Context Engineering Unlocks Agentic Loops and Long-Running Tasks
The holy grail of agents is the long-running loop. An agent that can work on a task for hours, even days, without losing coherence. That’s impossible without context engineering.
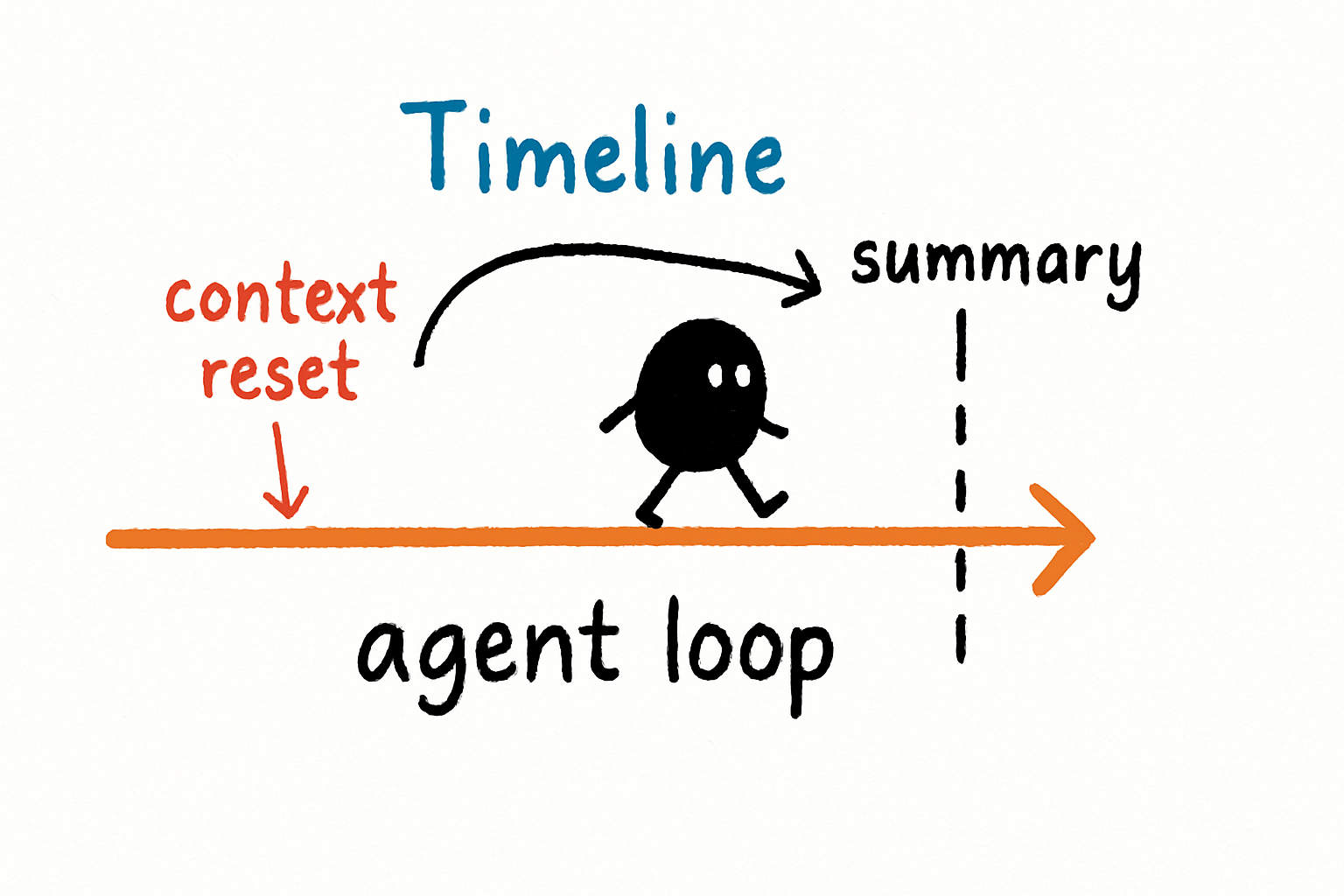
Think about what happens in a long-running loop. The agent takes an action, observes the result, reflects, and plans the next step. Each step adds context. After a hundred steps, you have a hundred-step history. If you feed that whole history into the next call, you’re asking the model to navigate a novel-length document. It won’t work.
Context engineering solves this by treating the loop as a sequence of bounded, independent calls. Each call has its own sized, scoped, and sequenced context. The agent doesn’t need to remember everything. It needs to remember the current state, the current goal, and the most recent observation. Everything else is archived.
I’ve built loops that run for 24 hours using this approach. The agent processes a batch of data, updates its state, and moves on. The context never grows beyond 2,000 tokens. The agent never drifts. It’s reliable because the context is engineered, not accumulated.
The Basis Set piece I mentioned earlier hits on this: agents need a new kind of infrastructure that manages state, memory, and context as first-class concerns. I’d go further. I think context management is the most important piece of that infrastructure. You can have the best state management in the world, but if you feed the model a garbage context, it will produce garbage output.
What’s the biggest misconception about context engineering? That it’s just prompt engineering with a fancy name. It’s not. Prompt engineering is about crafting the instructions. Context engineering is about managing the information the model sees at runtime. They’re complementary, but they’re different disciplines. Prompt engineering is static. Context engineering is dynamic, runtime, and system-level.
My take
Here’s the opinion that might piss off some people. Most of the hype around agentic frameworks — LangChain, CrewAI, AutoGPT — is premature. These frameworks give you orchestration, but they don’t give you context management. They assume the model can handle whatever you throw at it. They assume the context window is infinite. They assume the model’s attention is uniform. All of those assumptions are wrong.
I’ve seen teams spend months building elaborate multi-agent systems, only to have them fail because the context window turned into a mess. They blame the model. They blame the framework. They never look at the context.
My take is simple: before you build a multi-agent loop, get your context engineering right. Start with a single agent. Size, scope, and sequence its context. Add summarization. Add priority queues. Make it reliable. Then add complexity. If you skip this step, you’re building on sand.
The companies that will win in the agent space are not the ones with the best models. They’re the ones with the best context engineering. It’s boring. It’s infrastructure. But it’s the difference between a demo that works and a product that ships.
Key takeaways
- Context engineering is the systematic design and management of what goes into an LLM’s context window. It’s a runtime discipline, not a one-time prompt design.
- Context overload and drift are the primary failure modes for production agents. Symptoms include generic responses, repetition, and hallucination of irrelevant facts.
- The sizing, scoping, and sequencing framework gives you a repeatable way to engineer context for any agent task.
- Practical patterns include dynamic context windows, priority queues, and summarization pipelines. Start with summarization — it gives the biggest bang for the buck.
- Long-running agent loops are impossible without context engineering. Treat each loop iteration as a bounded, independent context call.
- Most agentic frameworks skip context management. That’s a mistake. Get context right before adding orchestration complexity.
What’s the one thing you should do after reading this? Audit your current agent’s context. Open a log of the last ten calls. Look at what’s in the context window. Is there irrelevant history? Is the system prompt buried? Are you paying for tokens you don’t need? If the answer to any of those is yes, you have a context engineering problem. And now you know how to fix it.